Python爬虫:学了requests库和re库之后能做的事情
本文共 1368 字,大约阅读时间需要 4 分钟。
学习的最好模式,就是学了就去马上用。上次是学完了urllib和re库之后尝试爬取了豆瓣分享的书单,那个时候发现urllib这个标准库还是不太好使。今天刚学了requests这个更好用的库之后,尝试和re一起使用爬取简书的第一页。
第一步:获取响应
使用的requests非常简单,非常人性化的get功能。import requests# 获取respnoseheaders = { 'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8', 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36', 'Host':'www.jianshu.com'}url = 'http://www.jianshu.com/'response = requests.get(url,headers)print(response.status_code)context = response.text 第二步:从网页中提取目标信息
这一步主要涉及到观察网页构造,然后使用正则表达式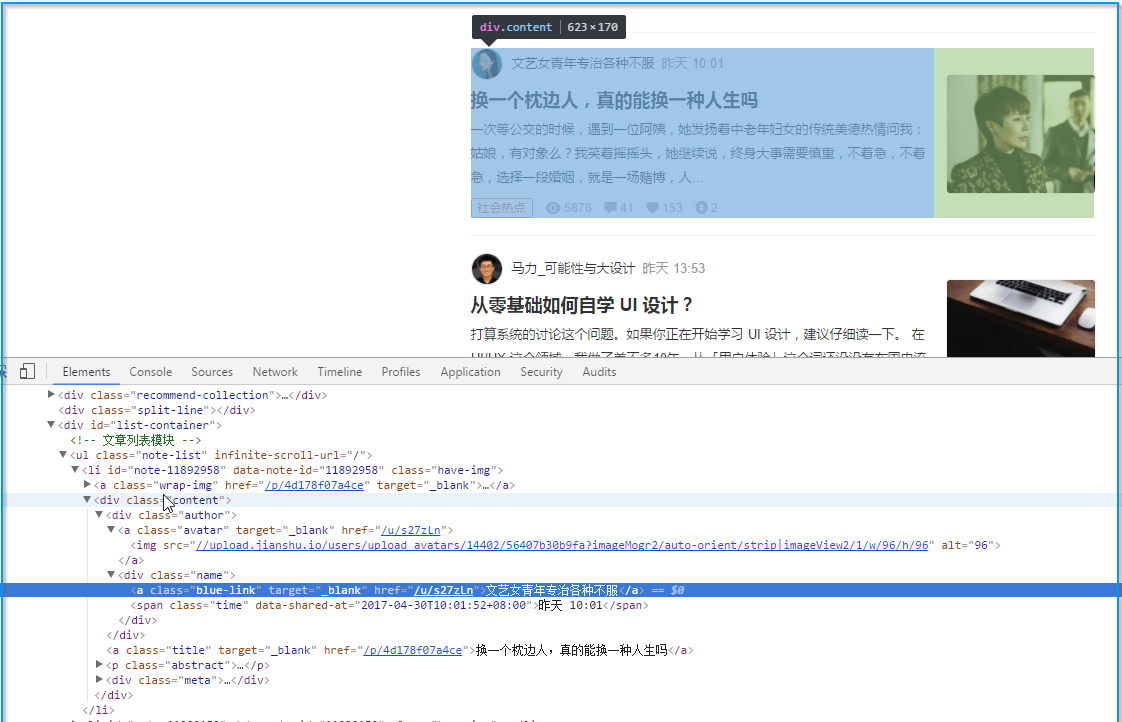
我的目标是:
- 作者
- 题目
- 文章简单内容
- 一些tag
先尝试构建获取作者的正则表达式
pattern = re.compile(' .*?>(.*?)',re.S)re.findall(pattern,context)#得到的结果['\n', '马力_可能性与大设计', '文艺女青年专治各种不服', '杨壳壳', '投资人日知录', '白发老蘭', '2020号', '无戒', '大胃黄咚咚', 'Aicuuu', '婉悦悠然', 'MadisonT', '小荐荐', '会啊哦的跳跳虫', '梦旅人rose', '吴益军子', '饱醉豚', '张涔汐', '笙和箫', '手机壳0207', '雪花如糖'] 一鼓作气,构建所有的目标信息的正则表达式模式:
pattern = re.compile(' .*?>(.*?).*?"title".*?>(.*?).*?act">(.*?) .*?/i>(.*?)',re.S)results = re.findall(pattern,context)for info in results: author,title,abstract,read_num = info author = re.sub('\s','',author) title = re.sub('\s','',title) print(author,title,abstract,read_num ) 
部分爬取结果
下一步学习计划
- re模块虽然好用,但是写起来还是麻烦,所以要去学习beautifulsoup等解析库,换一种提取数据方式
- 目前的数据没有采用合理的保存方式,所以下一步 要去了解一下如何合理保存数据
转载地址:http://mslja.baihongyu.com/
你可能感兴趣的文章
Kali-linux Arpspoof工具
查看>>
PDF文档页面如何重新排版?
查看>>
基于http协议使用protobuf进行前后端交互
查看>>
bash腳本編程之三 条件判断及算数运算
查看>>
php cookie
查看>>
linux下redis安装
查看>>
弃 Java 而使用 Kotlin 的你后悔了吗?| kotlin将会是最好的开发语言
查看>>
JavaScript 数据类型
查看>>
量子通信和大数据最有市场突破前景
查看>>
StringBuilder用法小结
查看>>
对‘初学者应该选择哪种编程语言’的回答——计算机达人成长之路(38)
查看>>
如何申请开通微信多客服功能
查看>>
Sr_C++_Engineer_(LBS_Engine@Global Map Dept.)
查看>>
非监督学习算法:异常检测
查看>>
App开发中甲乙方冲突会闹出啥后果?H5 APP 开发可以改变现状吗
查看>>
jquery的checkbox,radio,select等方法总结
查看>>
Linux coredump
查看>>
Ubuntu 10.04安装水晶(Mercury)无线网卡驱动
查看>>
Myeclipes快捷键
查看>>
我的友情链接
查看>>